[Python_크롤링] 파이썬 웹 크롤링 입문 (1) - 네이버 정보 가져오기(requests)
웹크롤링이 뭐냐!!!!
쉽게말해
인터넷에 존재하는 데이터를 컴퓨터 프로그램을 통해 자동화된 방법으로 수집하는 모든 작업을 말해요
들어만봐도 이게 뭐여... 이런 생각이 들겠지만,
유용하니 천천히 들여다 봅시다!

파이썬을 처음 접해보거나 오랜만에 접하는 사람들은 설치하고 와야해요!
제가 전에 포스트 한 게시물 확인하시면 쉽게 설치 가능할꺼에요~
https://crong-baby.tistory.com/4
[python] 파이썬 시작하기 (Windows)
다른 블로그 보면 너무 어렵다고 생각이 들어 공부 삼아 블로그를 만들어봅니다! 자 파이썬을 시작해볼까요? 전공자 이지만 비전공자가 보면 쉽게 따라할 수 있게 블로그 할게욬ㅋㅋ 파이썬을
crong-baby.tistory.com
자 본격적으로 크롤링을 해볼까요?!
1. 사이트 정보 가져오기
사이트 정보를 가져오기 위해 방법은 여러가지 입니다.
이 포스트는 requests 모듈을 통해서 사이트 정보를 가져올꺼에요~!
일딴 프로젝트에서 .py 파일을 새로 생성해줍니다.
(1) 모듈설치
현재 프로잭트의 터미널에서 requests 모듈을 설치할꺼에요~!
터미널 > 명령어 치고 엔터
(모듈 설치할 때 우리는 pip 라는 파이썬 패키지를 관리해주는 라이브러리 시스템을 이용할거에요~!)
명령어 : pip install requests

모듈이 잘 설치가 되어있는지 확인해야 겠죠?
확인방법 : pip list

자 모듈이 설치 되었으면, import를 통해 모듈이 잘 설치했는지도 확인해야합니다.
import requests #모듈을 가져오기

이상이 없으면 저렇게 될것이다.
자 이제 네이버 사이트 소스를 가져와 보자!!!
import requests #모듈을 가져오기
response = requests.get('https://www.naver.com/') #requests.get을 통해 naver에 있는 소스를 response 변수에 대입
print(response.text) #response에 있는 text를 모두 출력한다.
여기서 reponse변수명을 바꿔도 무관합니다.!!
ex)response -> test
소스 문법에 대해서는 소개하지 않겠습니다.
어후....
처음부터 뭔가 어려워 보이지만 간단합니다.

자 소스 입력을 했으면 실행을 해줘야합니다.

실행한 화면은 아래에 보일꺼에요!
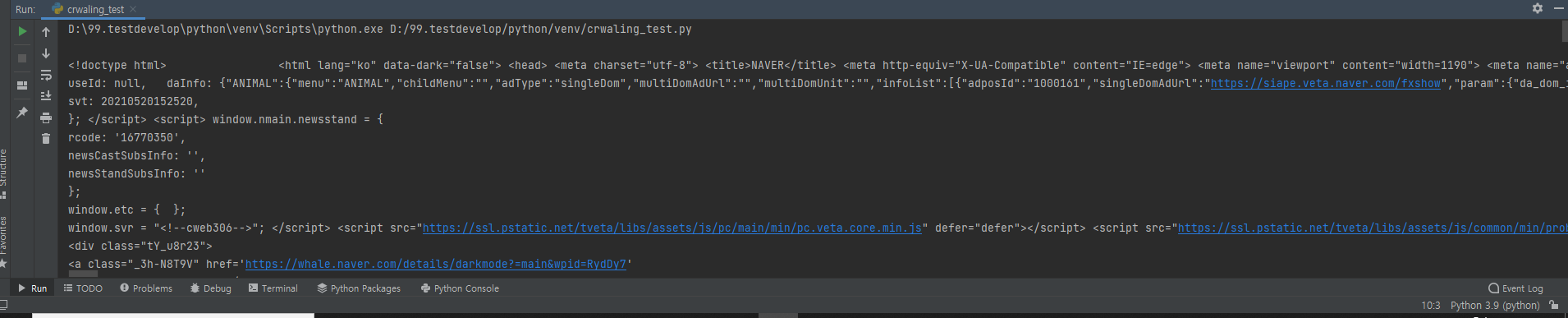
위 의 내용과 네이버 소스가 같은지 확인 해볼까요~?
웹페이지에서 F12누르면 소스가 나옵니다.
똑같네요~!오


문의 사항이나 궁금한 점 있으면 댓글이나 방명록에 작성 부탁드려요.
실시간으로 확인해서 제가 아는 선에서 가르쳐 드리도록 하겠습니다.
고생많았어요~!
